





晶圆级芯片,潜力无限。
当今,大模型参数已以“亿”为单位激增。仅两年,其所需计算能力便增加了千倍,超硬件迭代速度。
目前,AI大模型主要依赖GPU集群,但单芯片GPU有明显瓶颈:一是物理尺寸限制晶体管数量,即使采用先进工艺,算力提升也逼近摩尔定律极限;二是多芯片互联时,传输延迟与带宽损耗致整体性能无法线性增长。
因此,面对万亿参数模型,即使堆叠数千块英伟达H100,也难逃“算力不足、电费高昂”的困境。AI训练硬件分两大阵营:专用加速器(如Cerebras WSE-3和Tesla Dojo,基于晶圆级集成技术),以及GPU集群(如英伟达H100,基于传统架构)。
晶圆级芯片被认为是未来的突破口。
晶圆级芯片:两大巨头的竞技场
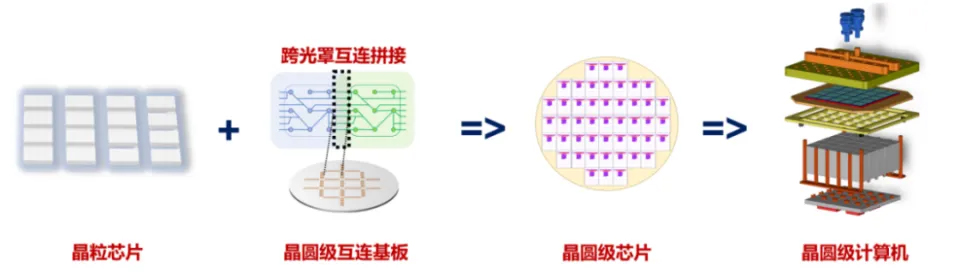
在传统的芯片制造过程中,一个晶圆经过光刻后会切割成众多小裸片(Die),这些裸片再被单独封装,形成完整的芯片。芯片算力的提升往往依赖于芯片面积的增加,因此,芯片制造商们一直致力于扩大芯片的面积。目前,高性能算力芯片的单Die尺寸大约为26x33=858mm²,接近曝光窗的大小。然而,芯片的最大尺寸受到曝光窗大小的限制,多年来曝光窗的尺寸未曾改变,这成了制约芯片算力增长的重要因素之一。
晶圆级芯片技术为解决这一难题提供了新的思路。通过制造一块无需切割的晶圆级互连基板,然后将设计好的常规裸片集成并封装在这块基板上,可以获得一块巨大的芯片。由于未切割的晶圆上的电路单元和金属互连排列更加紧密,因此形成了带宽更高、延时更短的互连结构。这相当于通过高性能互连和高密度集成构建了更强大的算力节点。因此,在相同的算力下,采用晶圆级芯片构建的算力集群相比传统的GPU集群,占地面积能缩小10到20倍以上,功耗也可以降低30%以上。
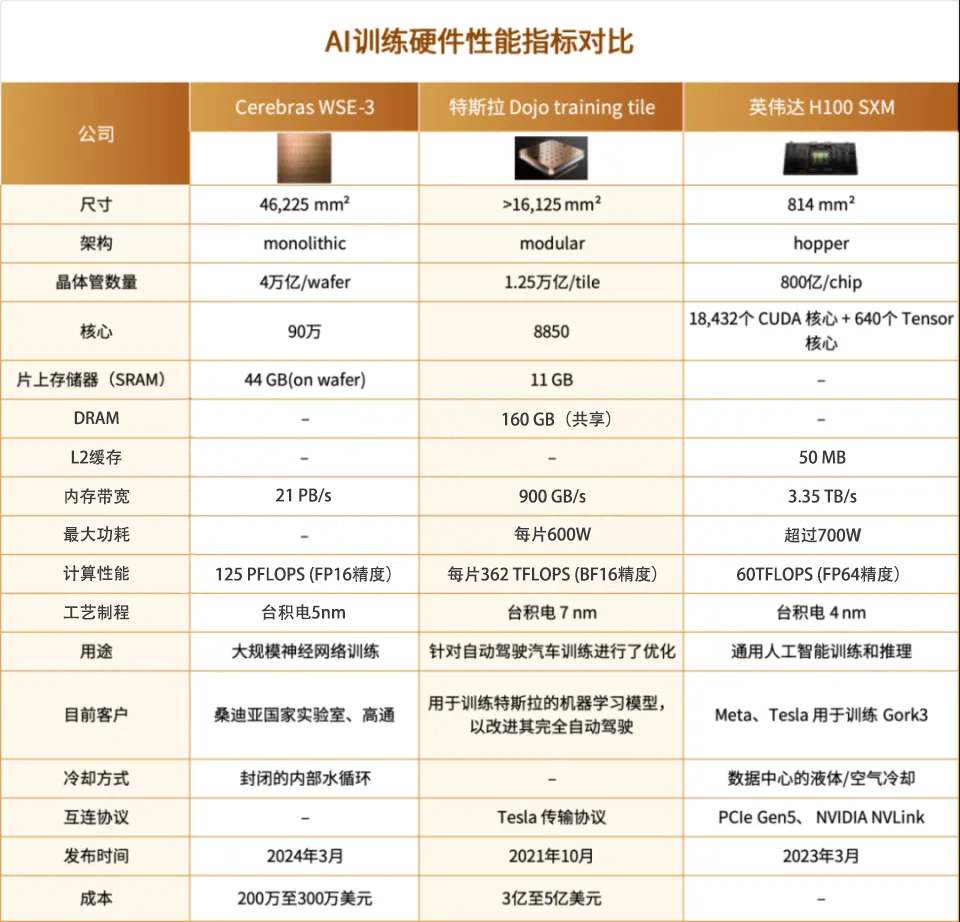
 全球两家公司已开发出晶圆级芯片产品,其中Cerebras自2015年成立以来,不断迭代,于2019年推出WES-1,目前已发展到第三代WES-3。该芯片采用台积电5nm工艺,拥有4万亿个晶体管,90万个AI核心,44GB缓存容量,支持高达1.2PB的片外内存。
全球两家公司已开发出晶圆级芯片产品,其中Cerebras自2015年成立以来,不断迭代,于2019年推出WES-1,目前已发展到第三代WES-3。该芯片采用台积电5nm工艺,拥有4万亿个晶体管,90万个AI核心,44GB缓存容量,支持高达1.2PB的片外内存。
WES-3的技术优势非常明显,它能够轻松训练出参数规模比GPT-4和Gemini大10倍的下一代领先大模型。在四颗芯片并联的情况下,WES-3仅需一天时间就能完成对700亿参数的模型进行调优,支持高达2048路的互连能力,同样在一天之内即可完成对Llama 700亿参数模型的训练。这些卓越的性能都集成在一块面积为215mm×215mm=46,225mm2的晶圆上。
如果这样的对比还不够直观,我们可以进一步看到:与英伟达的H100相比,WES-3的片上内存容量是H100的880倍,单芯片内存带宽达到H100的7000倍,核心数量是H100的52倍,片上互连带宽速度更是H100的3715倍。这些数据充分展示了WES-3在处理大规模数据和复杂计算任务方面的强大实力。
特斯拉的晶圆级芯片Dojo自2021年开始研发,采用Chiplet技术,在晶圆尺寸基板上集成25颗D1芯粒,单个Dojo拥有9Petaflops算力和每秒36TB带宽,专为全自动驾驶(FSD)模型训练定制,从25个D1芯粒组成1个训练瓦,6个训练瓦组成1个托盘,2个托盘组成1个机柜,10个机柜组成1套ExaPOD超算系统,提供1.1EFlops计算性能。
02 晶圆级芯片与GPU对比
既然单芯片GPU和晶圆级芯片在发展路径上已分道扬镳,在此我们将以Cerebras WSE-3、Dojo以及英伟达 H100为例,对这两种芯片架构在算力极限上的不同探索进行对比分析。通过这样的对比,我们可以更清晰地看到它们各自的优势与劣势,以及未来发展的可能方向。
 AI训练芯片GPU的性能主要通过每秒浮点运算次数(FLOPS)、内存带宽、延迟和吞吐量等关键指标评估。
AI训练芯片GPU的性能主要通过每秒浮点运算次数(FLOPS)、内存带宽、延迟和吞吐量等关键指标评估。
Cerebras WSE-3凭借其单片架构,在AI模型训练中展现出独特潜力。WSE-3的FP16训练峰值性能达到125 PFLOPS,可支持训练高达24万亿参数的AI模型,无需分区处理,提升了计算吞吐量。相比之下,英伟达H100采用模块化和分布式方法,单个H100 GPU提供60 TFLOPS FP64计算能力,八个互连的H100 GPU系统可实现超1 ExaFLOP的FP8 AI性能,但分布式架构存在数据传输问题,影响训练速度。
在AI训练表现中,WSE-3更擅长处理超大型模型。2048个WSE-3系统组成的集群训练Meta的700亿参数Llama 2 LLM仅需1天,速度提升30倍。WSE-3的单片架构显著降低了数据传输延迟,支持大规模并行计算和核心间低延迟通信,将软件复杂度降低90%,实时GenAI推理延迟降低10倍以上。
特斯拉Dojo Training Tile采用晶圆级集成,降低通信开销,跨区块扩展时仍有延迟。目前,Dojo可实现100纳秒的芯片间延迟,并针对自动驾驶训练优化了吞吐量,可同时处理100万个每秒36帧的视频流。英伟达H100基于Hopper架构,是当前最强大的AI训练GPU之一。