





HBM,挑战加倍
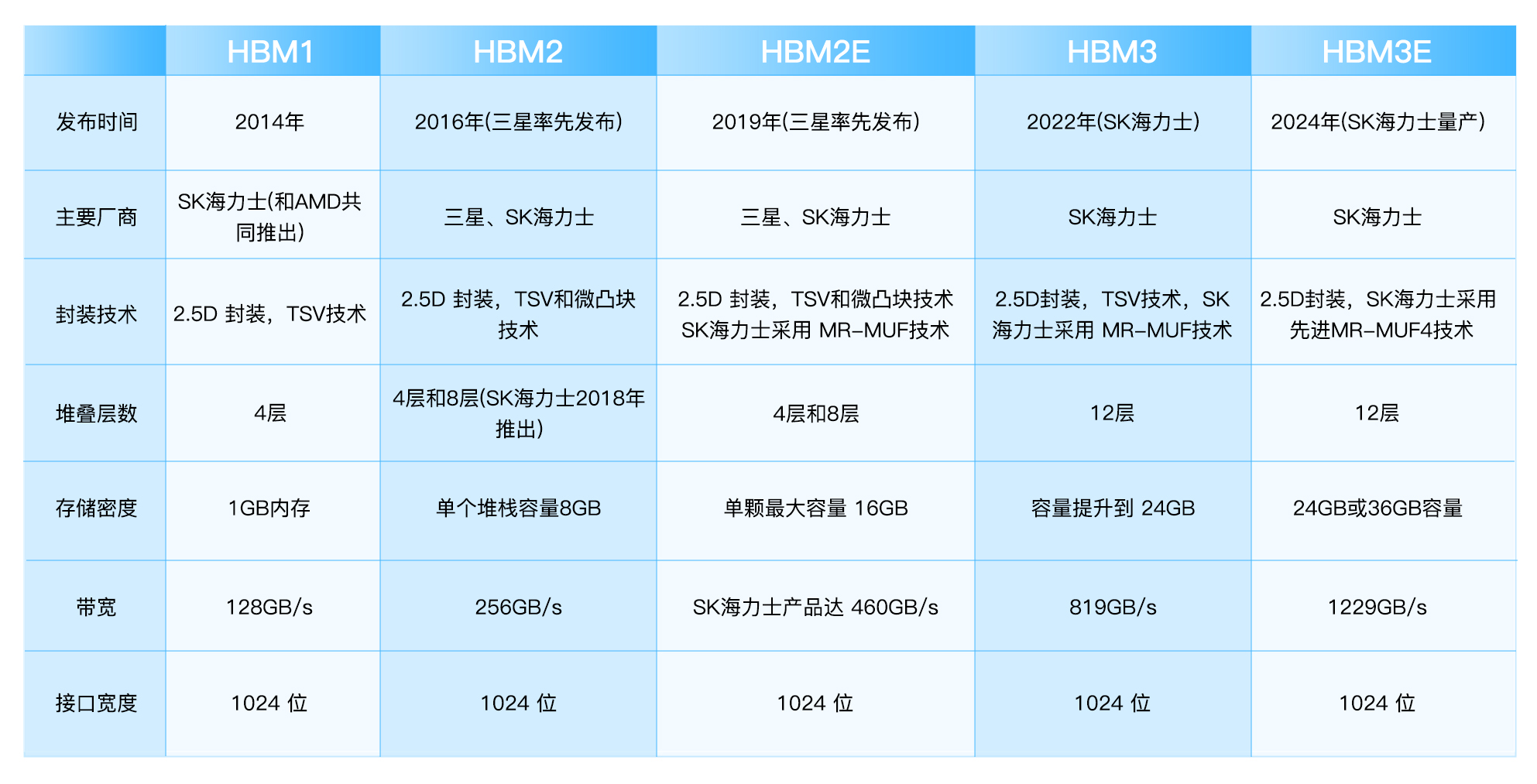
高带宽内存(HBM)作为下一代动态随机存取存储器(DRAM)技术,其核心创新在于采用了独特的3D堆叠结构。通过运用先进的封装技术,多个DRAM芯片(通常为4层、8层甚至12层)被垂直堆叠在一起。这种创新的结构设计使得HBM的数据传输速率,即带宽,远高于传统的内存解决方案,如GDDR等,从而大幅提升了数据传输效率。
 HBM(高带宽内存)因其卓越的高带宽和低延迟特性,已成为AI大模型训练与推理中不可或缺的关键组件。在AI芯片的架构中,HBM扮演着“L4缓存”的重要角色,它能够极大地提升数据的读写效率,有效缓解内存带宽的瓶颈问题,从而显著增强AI模型的运算能力,推动AI技术的不断进步。
HBM(高带宽内存)因其卓越的高带宽和低延迟特性,已成为AI大模型训练与推理中不可或缺的关键组件。在AI芯片的架构中,HBM扮演着“L4缓存”的重要角色,它能够极大地提升数据的读写效率,有效缓解内存带宽的瓶颈问题,从而显著增强AI模型的运算能力,推动AI技术的不断进步。
HBM市场,SK海力士独领风骚
SK海力士依托在HBM技术领域的卓越领先优势,在半导体行业中持续巩固并提升其市场地位。最新的市场研究数据表明,自2024年第二季度以来,SK海力士与美光在DRAM市场的份额呈现稳步增长态势,而三星电子的市场份额则逐渐缩减。特别是在HBM市场,曾与三星电子形成双雄对峙的格局已被打破,截至今年第一季度,双方的市场份额差距已显著扩大至两倍以上。
更为值得关注的是,在今年第二季度,SK海力士凭借DRAM及NAND闪存产品的销售额达到了约21.8万亿韩元,首次在销售额上超越三星电子(约为21.2万亿韩元),荣登全球存储芯片市场销售额的榜首。这一辉煌成就的取得,在很大程度上归功于其在HBM产品领域的出色表现和强大竞争力。
作为英伟达的主要独家供应商,尽管SK海力士在HBM市场初期的表现并不显眼,但随着全球范围内人工智能开发热潮的不断兴起,对于高性能、高效率计算存储产品的需求急剧增加,这也促使SK海力士在这一领域的增长势头异常迅猛。
在推动这一趋势的因素中,第五代高带宽内存HBM3E无疑扮演了关键角色。该产品以其卓越的高带宽和低功耗特性,在AI服务器、GPU等高性能计算领域得到了广泛的应用。从2023年到2024年,AMD、英伟达、微软和亚马逊等科技巨头纷纷竞相采购这一产品,而SK海力士作为全球唯一一家能够大规模生产HBM3E的厂商,其在2025年的8层及12层HBM3E产能已被预订一空。相比之下,三星电子因交付延迟而错失了良机,尤其是在AI市场应用最广泛的HBM3E领域,其市场份额从去年第二季度的41%急剧下滑至今年第二季度的17%。甚至有报道称,三星电子未能通过英伟达的第三次HBM3E认证。展望未来,光大证券预测HBM市场的需求将持续增长,进而推动整个存储产业链的发展。花旗证券也预计,SK海力士将继续在HBM市场中占据主导地位。显然,SK海力士有望在人工智能时代成为“存储器领域的霸主”。
存储厂商开发HBM替代方案
SK海力士表现强劲,行业其他厂商加速技术创新,探索HBM替代方案。
三星重启Z-NAND
搁置七年之后,三星电子决定重新启动其Z-NAND内存技术项目,将其定位为应对人工智能(AI)工作负载增长需求的高性能解决方案。这一决定在2025年美国未来内存与存储(FMS)论坛上正式对外公布,标志着三星重新进军高端企业存储市场。在这次活动中,三星内存业务执行副总裁Hwaseok Oh透露,公司正在全力以赴重新开发Z-NAND技术,目标是将其性能提升到传统NAND闪存的15倍,同时将功耗降低高达80%。即将面世的新一代Z-NAND将采用GPU发起的直接存储访问(GIDS)技术,使GPU能够直接从存储器获取数据,省去CPU或DRAM的参与。这种架构设计旨在最大限度地降低延迟,从而加速大型AI模型的训练和推理过程。
Z-NAND的重新崛起,不仅标志着技术的进步,更预示着整个存储行业的深刻变革。随着人工智能(AI)模型的快速演进,其数据需求已远超传统存储基础设施的承受能力。在现有的系统架构中,数据需先从固态硬盘(SSD)经过中央处理器(CPU)传输到动态随机存取存储器(DRAM),最终到达图形处理器(GPU)。这一繁琐的过程不仅严重限制了数据处理的速度,还增加了不必要的能源消耗。
为解决这一问题,三星推出了支持GIDS(GPU-Inside-DirectStorage)架构的创新技术。该架构通过优化数据传输路径,有效消除了传统存储层级带来的瓶颈,使得GPU能够直接将大型数据集从存储设备加载到视频随机存储器(VRAM)中。三星电子的专家Oh指出,这种直接集成的方式可以显著缩短大型语言模型(LLM)以及其他计算密集型AI应用的训练周期,从而大幅提高工作效率。
事实上,三星早在2018年就率先推出了Z-NAND技术,并首次应用于面向企业级和高性能计算(HPC)市场的SZ985Z-SSD。这款具有突破性的800GB固态硬盘,采用48层V-NAND闪存和超低延迟控制器,其顺序读取速度高达3200MB/s,随机读取性能达到750K每秒输入输出操作(IOPS),写入速度也高达170KIOPS,延迟均控制在20微秒以内。综合性能相比传统SSD提升了五倍以上,读取速度更是3位V-NAND的十倍之多。此外,SZ985还配备了1.5GB的节能LPDDR4DRAM,额定写入容量高达42PB,足以存储全高清电影840万次,凭借200万小时的平均故障间隔时间(MTBF),为用户提供了高度可靠的保障。
这一系列的技术革新不仅展现了三星在存储领域的领导力,也为未来AI及高性能计算应用的发展铺平了道路。可以预见,随着Z-NAND技术的进一步成熟和普及,它将在推动全球科技发展方面扮演越来越重要的角色。
X-HBM 架构重磅登场
NEO Semiconductor近期震撼发布了全球首项专为AI芯片设计的超高带宽内存(X-HBM)架构,这一创新成果基于公司自主研发的3D X-DRAM技术。X-HBM成功突破了传统HBM在带宽与容量方面的瓶颈,有望引领内存产业进入AI时代的“超级内存”新纪元。相比之下,目前仍在开发中、预计2030年量产的HBM5,仅能支持4K位数据总线和每芯片40Gbit的容量;韩国科学技术院(KAIST)最新研究指出,即使到2040年左右推出的HBM8,预计也只能达到16K位总线和每芯片80Gbit的容量。
而X-HBM却凭借其32K位总线和每芯片512Gbit的容量,使AI芯片设计人员能够直接跨越传统HBM技术需耗费十年时间才能逐步突破的性能障碍。值得一提的是,X-HBM的带宽达到现有内存技术的16倍,密度则为现有技术的10倍。其32Kbit数据总线与单芯片最高512Gbit的存储容量所带来的卓越性能,显著打破了传统HBM的局限,精准地满足了生成式AI与高性能计算日益增长的需求。
Saimemory开发堆叠式DRAM
由软银、英特尔与东京大学联手创立的Saimemory公司正在积极研发一种全新的堆叠式DRAM架构,其目标旨在成为HBM(高带宽内存)的直接替代品,甚至在性能上实现超越。这家新兴公司的技术重心集中于3D堆叠架构的优化,通过将多颗DRAM芯片垂直堆叠,并改进芯片间的互连技术(如运用英特尔的嵌入式多芯片互连桥接技术EMIB),不仅提升了存储容量,还降低了数据传输过程中的功耗。规划中,他们的目标产品将实现容量较传统DRAM至少提升一倍,功耗较HBM减少40%到50%,且生产成本将显著低于现有的HBM产品。这一创新有望为内存技术带来革命性的进步。
Saimemory 所选择的技术路径与三星、NEO Semiconductor 等企业形成了显著的差异。后者主要致力于容量的提升,力求实现单模块 512GB 的大容量目标;而 Saimemory 则更加专注于解决 AI 数据中心在电力消耗方面所面临的难题,这恰好与当前绿色计算的发展潮流相契合。
在技术合作方面,Saimemory 获得了来自多个合作伙伴的有力支持。英特尔凭借其在先进封装技术领域的深厚积累,为公司提供了关键的技术支持。东京大学等日本知名学术机构则贡献了他们在存储架构方面的专利技术。而软银更是以 30 亿日元的投资成为了公司的最大股东。
公司计划将初期获得的 150 亿日元研发资金主要用于原型设计及量产评估,力争在 2027 年之前完成这些关键任务,并预计在 2030 年实现技术的商业化应用。这一战略规划不仅展示了 Saimemory 对技术创新和应用落地的坚定决心,也为公司在未来市场竞争中占据有利地位奠定了坚实的基础。
闪迪联手SK海力士推进HBF高带宽闪存
近日,闪迪与SK海力士宣布签署一份谅解备忘录,双方将携手制定高带宽闪存(HighBandwidthFlash,HBF)的规范。此合作源自闪迪在今年二月份首次提出的HBF概念,这是一种专门为人工智能领域设计的创新型存储架构。其核心特色在于将3DNAND闪存与高带宽存储器(HBM)的技术优势相融合。按照计划,闪迪预计在2026年下半年推出首批采用HBF技术的内存样品,而集成此项技术的AI推理设备样品则预计在2027年初面市。这一合作预示着存储技术的新纪元,将为AI应用带来前所未有的高性能与效率。
作为以NAND闪存为基础的内存技术,HBF(High Bandwidth Flash)创新性地运用了类似HBM(High Bandwidth Memory)的封装形式。与成本较高的传统HBM相比,HBF不仅显著提升了存储容量,还大幅降低了成本,同时保留了数据在断电后仍能保存的非易失性特点。这一技术突破标志着业界首次成功将闪存的存储特性与类似DRAM(Dynamic Random Access Memory)的高带宽性能整合到单个堆栈中,有望彻底改变AI模型在处理大规模数据时的访问和处理方式。
相比完全依赖DRAM的传统HBM,HBF通过使用NAND闪存替代部分内存堆栈,在一定程度上牺牲了原始延迟,但实现了在成本与带宽上接近DRAM的基础上,将存储容量提升至传统HBM的8到16倍。此外,与需要持续供电来保存数据的DRAM不同,NAND闪存的非易失性使得HBF能够在更低能耗的情况下实现持久存储,从而在性能和能效上提供了更优的平衡。
多维度架构创新降低HBM依赖
厂商们在存储技术上不断创新,同时积极探索AI领域架构革新,以降低对HBM的依赖。
存算一体架构
上世纪40年代,现代史上首台计算机问世,随之催生了基于“存储-计算分离”原理的冯・诺依曼架构,这一架构此后成为芯片设计的重要基石,影响深远。在近70年的现代芯片行业发展历程中,尽管技术不断进步,多聚焦于软件与硬件的优化创新,计算机的底层架构却始终如一,未曾发生根本性变革。
存算一体(Processing-In-Memory, PIM 或 Compute-in-Memory, CIM)这一创新架构正是在当前技术背景下应运而生。其核心思想是将计算功能集成到存储器本身或附近,从而避开传统架构中“计算―存储―数据搬运”这一固有的瓶颈。通过在存储单元内部直接嵌入运算单元,存算一体架构在物理上极大缩短了数据传输的距离,成功地将计算与存储单元融合在一起,优化了数据传输路径,并突破了传统芯片在算力上的限制。这不仅大幅缩短了系统的响应时间,还使得能效比得到显著提升。一旦该技术成熟,有望将高带宽内存的依赖度降低一个数量级,甚至部分替代HBM的功能。
华为的 AI 突破性技术成果
华为近期推出的UCM(推理记忆数据管理器)是一款以KV Cache(键值缓存)为核心的创新推理加速套件。该套件整合了多种先进的缓存加速算法工具,能够对推理过程中生成的KV Cache记忆数据进行智能分级管理,极大地扩展了推理上下文的窗口,从而实现了高吞吐量和低延迟的推理体验,显著降低了每个Token(词元)的推理成本。凭借这一前瞻性的架构设计,UCM不仅减少了对高带宽内存(HBM)的依赖,还大幅提升了国产大模型的推理性能,为推理技术带来了新的突破。
未来将是多层级架构的时代
在训练与推理的场景中,算力与存储无疑是最先受益的领域,它们将成为决定未来十年AI竞争格局的核心因素。与GPGPU产品的发展轨迹相似,HBM(尤其是HBM3及更高规格)的需求正持续攀升,且长期由国外厂商主导市场。2025年初,HBM3芯片的现货价格相较2024年初惊人地暴涨了300%,而单台AI服务器的DRAM使用量更是达到了传统服务器的8倍。从市场格局来看,海外厂商依旧占据着主导地位:SK海力士以53%的市场份额遥遥领先,并且率先实现了HBM3E的量产;三星电子紧随其后,占据38%的市场份额,并计划在2025年将HBM的供应量提升至上一年的两倍;美光科技目前市场份额为10%,其目标是在2025年将市场占有率提升至20%以上。
尽管HBM(高带宽内存)凭借其卓越的性能在高端AI(人工智能)应用领域稳固了自身地位,但其他内存技术在成本控制、性能提升以及功耗优化方面不断取得进展,这可能使HBM在未来面临来自新兴技术的竞争压力。然而,在短期内,HBM仍然是满足高带宽需求场景的首选方案。从长远来看,市场将随着技术的演进和应用需求的变化而持续调整和优化。未来的AI内存市场不会是简单的“替代与被替代”的关系,HBM的替代方案将呈现出“架构哲学的多样性”,而非单一的技术迭代。可以预见,在AI计算和内存领域,不会出现全面取代HBM的“唯一赢家”,而是会更加复杂、分散,并紧密贴合具体应用场景的内存层级结构。单一内存解决方案主导高性能计算的时代正在逐渐成为过去。未来的AI内存版图将是一个异构多元的层级体系:HBM将继续专注于训练场景;PIM(处理内内存)内存将服务于高能效推理;专用片上内存架构将适应超低延迟的应用需求;新型堆叠DRAM(动态随机存取存储器)与光子互连等技术也将在系统中发挥重要作用。各类技术针对特定工作负载进行精准优化,共同构成AI时代的内存生态。